Globoke nevronske mreže
Globoke nevronske mreže
Razlaga, izposojena iz Pumic: Kako delujejo globoke nevronske mreže
Globoko učenje je veja strojnega učenja, ki kot model uporablja globoke nevronske mreže — ogromne nevronske mreže z ducatom nivojev nevronov. Te so zaslužne za odmevnost umetne inteligence v zadnjih letih. Začelo se je s prepoznavanjem slik in zvočnih posnetkov, nadaljevalo z generiranjem slik, pa vse do velikih jezikovnih modelov, ki so sposobni generirati besedila, ki jih je težko ločiti od človeških. (Veliki jezikovni model je samovšečno generiral zaključek gornjega stavka, od »ki so« naprej.)
Poglavje 1: Uvod
Palčkom smo določali poklice na podlagi njihovega izgleda in orodja, ki so ga nosili. Ko smo isto nalogo zastavili računalniku, smo vsakega palčka že opisali s seznamom lastnosti — ima lopatko, ima lučko, kakšne barve so njegovi čevlji in pas, na katero stran je obrnjena njegova kapa... Bi uspel prepoznati poklice palčkov tudi brez teh podatkov, neposredno iz slik?
Težko, ne? Slika je opisana z barvami posamičnih točk. V primeru palčkov vemo, katere točke so bele in katere črne; bi res mogel iz takšnih podatkov razbirati njihove poklice?
S hišami, svetišči ali drugimi slikami je še težje: lastnosti so manj očitne, bolj skrite v sliko. Da, ko gre za tradicionalne slovenske hiše, nam oblika strehe in njen material povesta kar veliko, a ne nujno vsega. Pri svetiščih pa gre pogosto za »vtis«. Za določeno svetišče nekako vemo, da je budistično, ne hindujsko, čeprav — vsaj zahodnjaki — morda ne znamo eksplicitno pojasniti, zakaj. Naš vtis je torej impliciten, ne znamo ga opisati s konkretnimi lastnostmi.
Tudi predstavitev slik — in drugih podatkov, kot so besedila in zvočni posnetki — v računalniku je na nek način impliciten. Globoki modeli predstavijo sliko z določenim številom spremenljivk, recimo 2048 spremenljivkami, katerih pomena ne znamo pojasniti, vemo pa, da se v njih skriva opis vsebine slike, ki je dovolj dober, da ne loči le mačk od psov, temveč tudi prekmursko sliko od kraške in budistično svetišče od hindujskega.
Številke torej predstavljajo nekakšen »profil« slike. Temu smo se približali ob Slovenskih priimkih, kjer je bila vsaka občina predstavljena s pogostostjo 200 priimkov. Vsak zase ni nosil veliko informacije, prav tako se nismo ukvarjali s tem, zakaj v neki občini nek specifični priimek, vsi skupaj pa so vsebovali opis geografske lege in zgodovinskega razvoja občine.
Poglavje 2: Nevronske mreže
Nevronske mreže so sestavljene iz nevronov. Začnimo torej z … nekoč je bil nevron.
En nevron
Vzemimo človeka, ki pride k zdravniku, ker se slabo počuti in vstopivši v ordinacijo začne naštevati vse svojesimptome: kašlja, ima nekaj vročine, boli ga glava, vendar ne bruha, po trebuhu ima neke izpuščaje, ki pa so že od prej … Zdravnik posluša in sešteva. Recimo, da gre za specialista za gripo, ki ga na koncu koncev zanima le, ali bi oseba lahko imela gripo ali ne. Vsak simptom mu doda ali odvzame nekaj točk, na koncu pa sešteje vse točke in če je njihova vsota večja od nekega praga, reče, da gre za gripo.
Kajpada poenostavljamo. Simptomi so medsebojno povezani ali pa se izključujejo in zdravnik vse to ve. Poleg tega vidi človeka pred sabo, pozna njegovo zgodovino, druge bolezni...
Zdravniki tega seveda ne počnejo zavestno, vseeno pa uporabljajo nek podzavesten model seštevanja dokazov in protidokazov.
Tako zdravnik, ekspert iz mesa in kosti. Bi se lahko tega naučil računalnik? Naučil v smislu sam sestavil model za zaznavanje gripe? Preprosta pot je, da se loti tako kot Računalnik iz bombonov, ki je v začetku streljal kozle, potem pa postopno prilagajal svoje odločitve glede na to, kako so se izkazale. Model bi torej priredil simptomom naključne uteži. Sprejel bi prvega pacienta, izdelal napoved, nato pa se pozanimal o tem, ali je bila napoved pravilna. Po tem bi prilagodil uteži simptomov: če je imel pacient gripo, bi povečal uteži prisotnim simptomom in zmanjšal uteži simptomov, ki jih pacient ni imel. Sicer pa obratno. Po dovolj učnih primerih bi bil model lahko že kar dober.

Logistična funkcija
Če bi želeli napovedovati verjetnost gripe, bi dodali še formulo, s katero bi spremenili vsoto uteži, ki je lahko poljubno velika in celo negativna, v verjetnost. Ker mora biti verjetnost med 0 in 1, je popularna logistična funkcija, ki ima obliko , kjer je vsota uteži. Če je vsota uteži 0, bo dala ta formula verjetnost 0.5. Očitno: je 1, torej smo dobili . Ko je vsota vedno večja in je vedno manjši in verjetnost vedno bližje 1, saj v imenovalcu k 1 prištejemo nekaj zelo majhnega. In obratno: bolj ko je vsota negativna, bolj je ogromen, torej je imenovalec vedno večji in verjetnost vedno bližja 0.
Temo kar smo opisali, je nevron. Če prihajamo iz strojnege učenja in umetne inteligence. Statistiki bi v tem prepoznali logistično regresijo, ta pa je vrsta linearnega modela.
Nevron lahko narišemo tako.
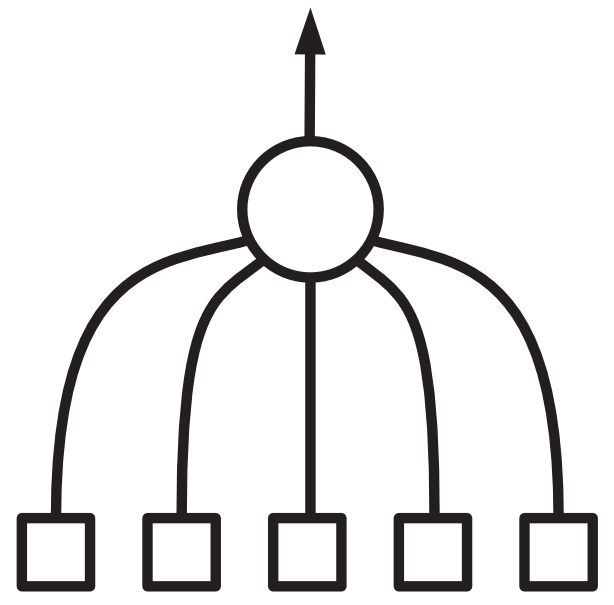
Tale dobi pet vhodov (recimo simptomov); vsakega pomnoži z njegovo utežjo, rezultat sešteje, z logistično funkcijo pretvori v verjetnost in jo vrne.
Več nevronov
Zdravnik, ki prepoznava le gripo, ne bi imel veliko obiskovalcev. Lahko bi se znašel tako, da bi šel v španovijo z enako omejenimi kolegi: zdravnikom, ki prepoznava pljučnico, zdravnikom, ki prepozna kovid, pa takšnim, ki prepozna norice, in tremi, ki so specializirani vsak za svojo vrsto trebušne viroze. Vsak od njih bi se lahko natreniral na svojem podatkovnem naboru in vsak bi imel svoj model za svojo bolezen.
Ob pisanju tega odstavka sem se zavedel, da bi tem ljudem komaj lahko rekli zdravniki. Bolj prepoznavalci posamičnih bolezni. Vseeno nadajujmo, problem pa zastavimo nekoliko drugače: naša naloga bo povedati, ali je oseba, s katero imamo opravka, bolna ali ne. Za katero bolezen gre, nas ne bo zanimalo.
Naloga je navidez podobna, zahteva le še, da ima ta nenavadna ordinacija vrhovnega zdravnika, ki zbere diagnoze področnih ekspertov. A hkrati z drugo nalogo bo prišel tudi drug tip podatkov: če smo poprej o vsakem pacientu vedeli ali ima posamično bolezen ali ne, bomo zdaj izvedeli le, ali je bolan ali ne. Spomnimo se, kako so se urili področni eksperti: oni za gripo je popravil svoje uteži glede na to, ali ima oseba gripo in oni za pljučnico glede na to, ali ima oseba pljučnico. Teh podatkov zdaj ni: vemo le, ali je oseba bolna.
Seveda bi lahko ravnali podobno kot prej. Pozabili bi na specialiste za gripe in kovide. Vzeli bi le enega eksperta, ki ne bi bil specifičen za posamične bolezni, temveč bi na podlagi vseh simptomov natreniral svoje uteži glede na to, ali je oseba bolna. To bi morda delovalo, morda ne: morda vsak simptom zase ne pomeni ničesar, temveč nastopajo le v kombinacijah. Glavobol, recimo, pomeni bolezen le, če ga spremlja trganje po sklepih in vročina (v tem primer gre za gripo) ali če ga spremlja vročina in izguba voha in okusa (neka stara različica kovida) ali bolečina v prsih in težko dihanje (pljučnica). Sam zase pa glavobol pomeni le dehidracijo ali danes-sem-čisto-zategnjen, kar ni bolezen.
Po tem razmisleku bi bilo očitno smiselno obdržati neko strukturo: čeprav nas bo na koncu zanimalo le, ali je oseba bolna ali ne, bomo naredili dvonivojski model, kjer bo prvi nivo napovedoval posamične bolezni, drugi pa jih združeval v končno odločitev.
Nevronska mreža
Ideja si zasluži nov naslov: taki strukturi rečemo nevronska mreža.
Predstavljajmo si, da vmesni nevroni niso le trije, temveč jih je, recimo, deset. Tako malo smo jih narisali le, da slika ni preč našarjena.
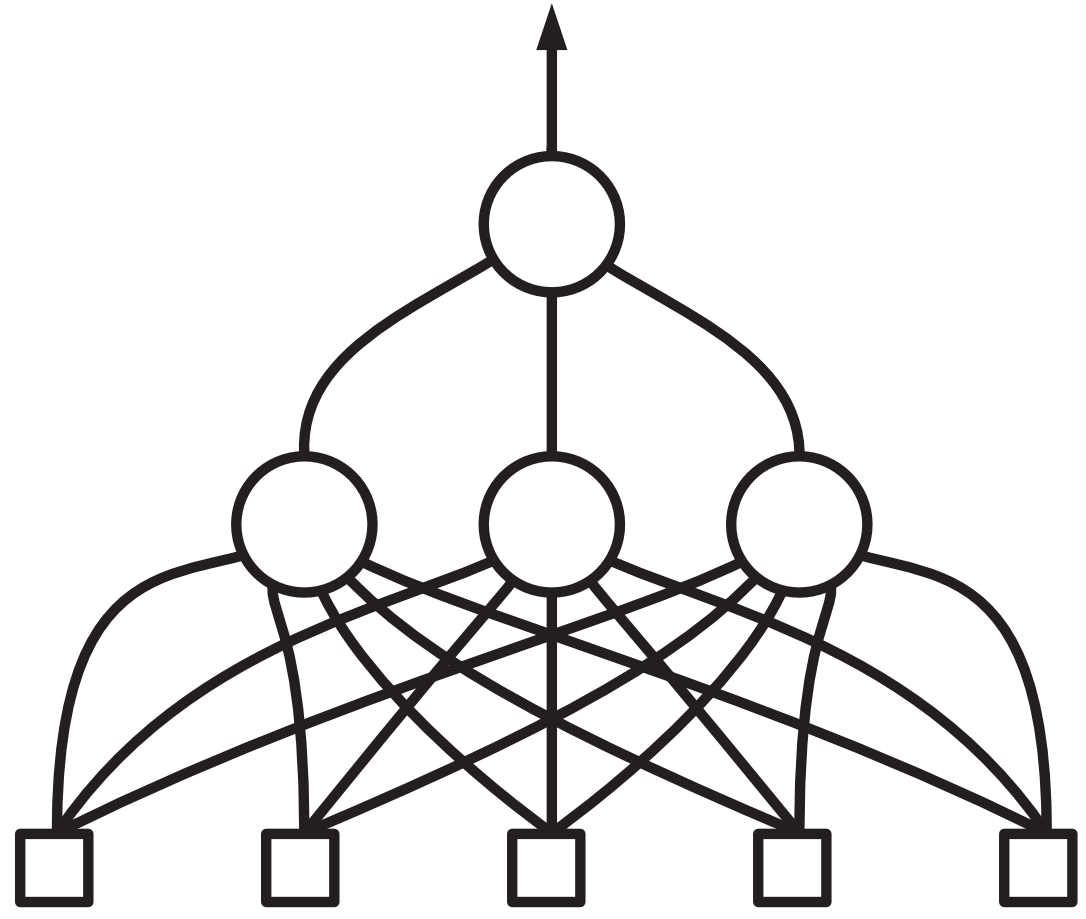
Da preženemo morebitno nelagodje ob branju tega odstavka, izdajmo: kasneje se bo izkazalo, da nevroni na prvem nivoju ne vedo, za katere bolezni se specializirajo
V nevrone na prvem nivoju vstopajo podatki o simptomih — vsak nevron dobi vse simptome. Nevroni na prvem nivoju seštejejo uteži simptomov — vsak za svojo posamično bolezen. Tako napovedo ali ima pacient gripo, pljučnico, kovid in tako naprej. Nekateri med njimi morda niti ne napovedujejo bolezni, temveč stanja kot dehidracija, zaležanost, preobremenjenost.
Na gornjem nivoju je nevron, ki prejme napovedi prvih nivojev in jih združi v končno napoved. Pri tem, tako kot vsak nevron, uporabi uteži: toliko in toliko točk, če nevron, napovedan za gripo, napoveduje gripo, toliko in toliko za specialista za pljučnico … Prav tako upošteva tudi dehidracijo in zaležanost: če specialist za dehidracijo pravi, da je človek le dehidriran, mu bo »vrhovni nevron« pač odvzel določeno število točk in zmanjšal (napovedano) verjetnost bolezni.
Gre za postopek učenja, ki mu rečemo vzvratno širjenje napake (backpropagation). Za napako izvemo ob izhodu iz mreže, potem pa se njene posledice — kazni in nagrade — širijo po mreži nazaj.
Ko smo si izmislili posamični nevron, smo našli tudi način za njegovo urjenje: ko prejme pacienta, spreminja uteži glede na pravilnost ali nepravilnost napovedi. Tu ravnamo enako. Ko za (učni) primer izvemo, ali je bil v resnici bolan ali ne, »vrhovni nevron« nagradi ali kaznuje eksperte, torej zmanjša ali poveča teže, ki jih daje mnenju ekspertov — nevronov na prvem nivoju. Eksperti pa ravnajo podobno: kadar so »kaznovani« s strani »vrhovnrga nevrona«, kaznujejo simptome, ki so jim nakopali to kazen (tako da spremenijo njihove uteži), in nagradijo simptome, ki so jih odvračali od odločitve, ki je vodila h kazni. In obratno, če je ekspert nagrajen, nagradi simptome, ki so vodili v to odločitev in kaznuje simptome, ki so ga odvračali od nje.
Ne prezrimo tudi, da so uteži ekspertov lahko tudi negativne, če gre za eksperta, ki dokazuje, da nekdo ni bolan.
Zamolčali smo — razen v opazki ob robu — da na ta način ne moremo uriti vmesnih ekspertov za specifične bolezni. Nobenega od ekspertov ne moremo izuriti za gripo, če za posamičnega pacienta vemo le, ali je bolan ali ne, ne pa, katero bolezen (gripo ali kaj drugega) ima.
Še več: spomnimo se, da so eksperti v začetku streljali kozle. Zdaj bomo storili enako: v začetku bodo vse uteži naključne. Nihče ne bo vedel, kdo napoveduje kaj. Delali bomo nesmiselne odločitve ter delili nagradi in kazni.
Sčasoma se bo zgodilo nekaj zanimivega: mreža se bo organizirala. Recimo, da je eden od nevronov na prvem nivoju slučajno nekoliko — morda čisto čisto malo — nagnjen k napovedovanju gripe. Nekoč bo prišel pacient z gripo, oni prvi bo slučajno nakazal, da bi lahko šlo za gripo in za to prejel nagrado. Posledično bo nagradil simptome gripe in naslednjič nekoliko odločneje napovedoval gripo (ali pa napovedal, da ne gre za gripo) in bil za to nagrajevan. Tako bo postajal vedno večji specialist za gripo.
Morda se bo našel nek drugi nevron, ki bo v začetku po naključju nagnjen k napovedovanju dehidracije in posledično sčasom postal specialist zanjo. Tretji se bo slučajno specializiral za pljučnico.
Da bi to delovalo, potrebujemo dovolj nevronov na prvem nivoju, potem pa bo sreča prej ko slej naredila svoje.
Nevronov na prvem nivoju torej ne treniramo načrtno za posamične bolezni. In če nas na koncu zanima le, ali je človek zdrav ali bolan, nas pravzaprav niti ne zanima, kaj počnejo ti, vmesni nevroni. Vemo, da so specializirani za različne bolezni in druga stanj. Kdo za katero — nam ni mar. Pravzaprav niti ni nujno, da je to možno razbrati. Da, lahko bi opazovali, kako razporejajo svoje uteži in v kakem od njih bi lahko razpoznali pljučničarja, za večino pa njihovih kombinacij uteži morda niti ne bi prepoznali.
Najlepše je, da nas to sploh ne moti. Prvemu nivoju rečemo preprosto skriti nivo (hidden layer), zadnjemu pa izhodni nivo (output layer).
Manjša pomanjkljivost: urjenje takšne mreže zahteva več podatkov. Skriti nevroni se morajo pač specializirati, kazni in nagrade pa so preveč posredne, da bi dale hitre rezultate.
Globoke nevronske mreže
Kaj pa, če bi dodali še en skriti nivo? Se pravi, nevroni na prvem nivoju ne bi sporočali svojih odločitev izhodnemu nevronu, temveč novemu nivoji skritih nevronov? Vsak iz prvega nivoja vsem iz drugega nivoja? Šele nevroni na drugem nivoju bi komunicirali s končnim, izhodnim nevronom?
Spet si predstavljajmo, da je v vsaki vrstici veliko več nevronov. Pri tem ni nujno, da v vseh vrsticah enako.
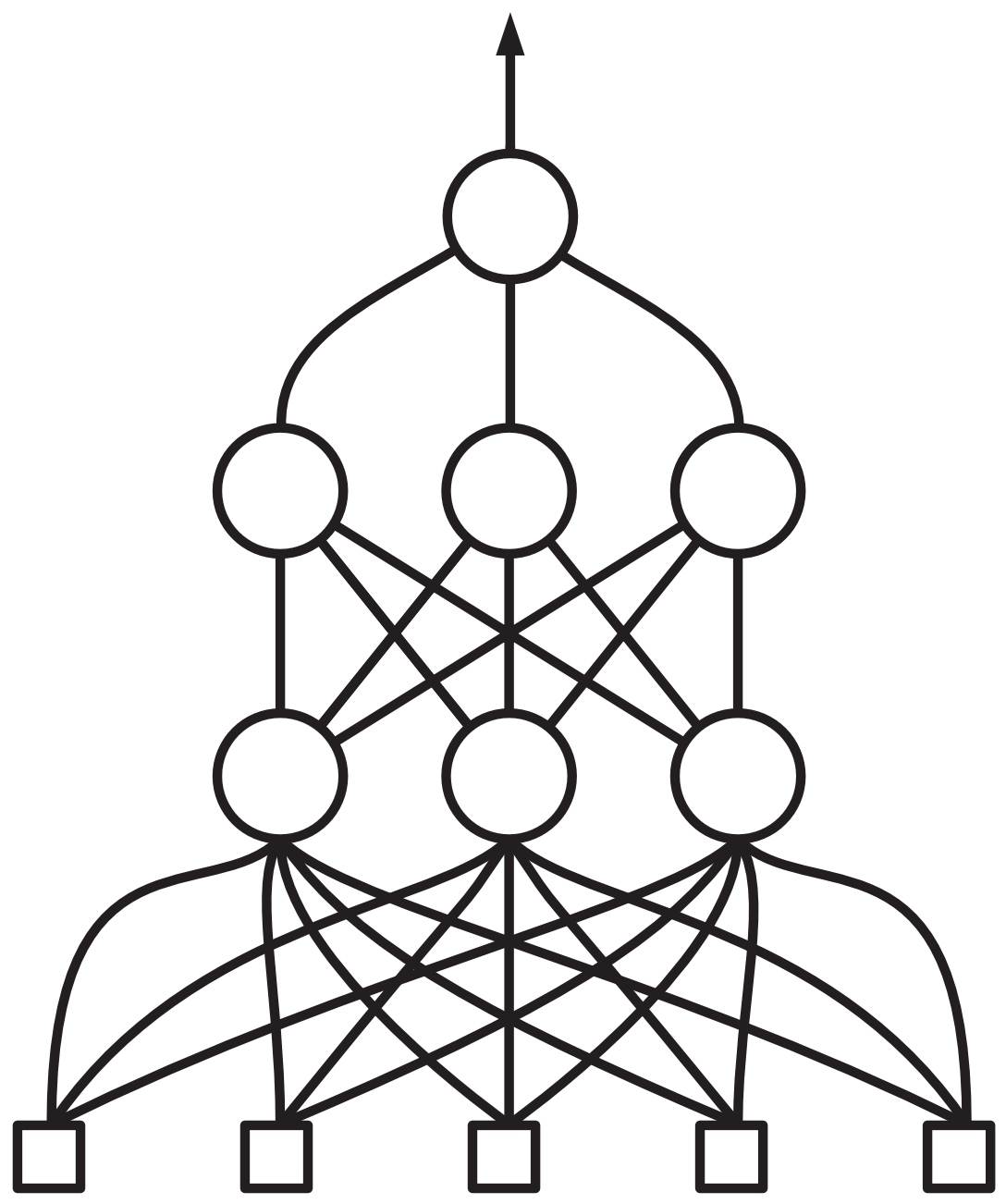
Je ta komplikacija res potrebna? Odvisno od tega, kako zahteven problem želimo reševati s pomočjo nevronske mreže. In koliko podatkov imamo, saj bo učenje take mreže še zahtevnejše. Za napovedovanje bolezni … morda ne.
Nekateri so se vprašali, kaj če bi naredili še en … pravzaprav ne še en, temveč še več skritih nivojev. Da, megalomani so rinili v mreže z, recimo, ducatom skritih nivojev.
To seveda ni delovalo. Za začetek zato, ker za urjenje takšne mreže preprosto niso imeli dovolj podatkov.
Preteklik je tu na mestu. Zdaj deluje, saj jih imamo. Vmes pa je bilo še nekaj teoretičnega in tehnološkega napredka.
Nakazali smo, da bi bil vsak nevron prejme odločitve vseh nivojev na prejšnjem nivoju — tako kot vsi nevroni na prvem nivoju prejmejo vse simptome. To bi pomenilo ogromno uteži in več ko je uteži, več podatkov potrebujemo za učenje. Izkazalo se je, da to ni potrebno.
Če želimo narediti nevronsko mrežo za prepoznavanje vsebine slik, bomo organizirali povezave tako, da bodo povzemale lokalne informacije. Vhod, »simptomi«, bodo barve posamičnih točk slike. Smiselno je povezovati bližnje točke slike, torej naj vsak nevron dobi podatke o barvi nekaj sosednjih točk. Tako bodo lahko nevroni na prvih nivojih kombinirali sosednje točke v črtice. Tisti na naslednjem bodo združevali izhode prvega nivoja, črtice, v črte, na naslednjih nivojih se bodo te črte povezovale v vedno večje strukture. Na višjih nivojih se strukture kombinirajo v vedno bolj kompleksne oblike: tam lahko opazimo oval, ki vsebujejo dva simetrično postavljena kroga (oči?), pod katerima je ena bolj trikotna (nos?) in spodaj še ena daljša in vodoravnejša (usta?).
Nivojem mreže, združujejo podatke iz nevronov, ki predstavljajo sosednje dele slike, rečemo konvolucijski nivoji. Za različne potrebe so si izmislili različne druge strukture mreže. V mrežah, ki obdelujejo zaporedja, na primer besedila, je smiselno povezovati zadnjih nekaj besed, zato je vsak nevron povezan z nekaj »prejšnjimi«; to so rekurzivni nivoji, saj se vračajo »nazaj«. V besedilih se izkaže tudi, da si je potrebno zapomniti reči, ki so nastopale že precej prej v besedilu, kar dosežemo z mehanizmi pozornosti (attention) — deli mreže, ki pomnijo določen podatek, dokler se ne odločijo, da ga je potrebno pozabiti.
Poleg različnih struktur so razvili tudi različne metode učenja — različne načine spreminjanja, prilagajanja uteži. Tudi logistična funkcija ni edina možna funkcija, ki jo pripnemo na izhode nevronov. Za nekatere naloge so se izkazale boljše funkcije drugačnih oblik.
Najpomembnejši pa so: podatki. Globoke nevronske mreže imajo še vedno milijone, celo milijarde uteži, ki jih je potrebno nastaviti, kar zahteva ogromno podatkov. Seveda nimamo podatkov o milijardi oseb z gripo, a za napovedovanje gripe tako ali tako ni potrebno izuriti globoke nevronske mreže. Globoko nevronsko mrežo potrebujemo za prepoznavanje objektov na slikah — teh pa imajo velika podjetja tudi milijarde, če je treba. Podobno velja za nevronske mreže, ki obdelujejo besedila, zvočne posnetke, video posnetke: takšne mreže zmoremo sestaviti predvsem zato, ker se je zanje nabralo dovolj podatkov.
Poglavje 3: Vložitve
Ostanimo še malo pri slikah.
Predstavljajmo si torej nevronsko mrežo, ki jo bomo izurili za to, da za dano sliko ugotovi, ali je na njej mačka ali ne. Na vhodu dobi barve točk, sledi ducat skritih nivojev z nevroni, povezanimi, kakor morajo biti pač povezani nevroni, če želimo prepoznavati slike, na izhodih iz nevronov uporabljamo primerne funkcije, uporabimo primeren postopek prilagajanja uteži … sami detajli, ki nas ne zanimajo. Verjemimo, da bomo dobili mrežo, ki bo znala prepoznavati slike mačk.
Spomnimo se, kako je videti nevronska mreža: nevroni iz zadnjega skritega nivoja — denimo, da bo tam kakih 2048 nevronov — so povezani z izhodnim nevronom. Ta dobi na svoj vhod izhode iz teh 2048 nevronov, torej 2048 številk, ki predstavljajo zbrane končne, predelane »simptome«, da gre na sliki za mačko. Izračuna ustrezno uteženo vsoto in če je rezultat, na primer, večji od 0, je na sliki mačka.
Zdaj pa se poskusimo naučiti, ali je na sliki hiša. Namesto, da bi začeli z naključnimi utežmi, bomo vzeli kar uteži, ki smo jih uporabili za določanje mačk in jih postopno »pretrenirali« na hiše. Strategija se zdi smiselna — in tudi v praksi se obnese. Zakaj? Spomnimo se, kaj smo povedali o prepoznavanju slik: na spodnjih nivojih povezuje točke v črtice, te v črte, nato v abstraktnejše oblike. Na nekem nivoju se seveda pojavi razlika med mačkami in hišami, nižji nivoji pa ostajajo enaki. Če gremo z mačk na hiše, se bodo pretežno »prekvalificirali« le gornji nivoji.
Ko opravimo s hišami, poskusimo naučiti mrežo, da bo prepoznavala oblake.
Pravzaprav: zakaj je ne bi učili več kategorij hkrati? Z več izhodnimi nevroni — enim za mačke, drugim za hiše, tretjim za oblake, četrtim za slike zemljevidov in petim za obraze … ter stotim za nekaj stotega? Naloga mreže je, da se vedno »sproži« tisti izhodni nevron, ki ustreza vsebini podane slike. Uteži prilagajamo glede na vse izhodne nevrone: če je na sliki mačka in se je sprožil nevron za hiše, bo ta kaznoval nevrone, ki so bili aktivni. Če se je sprožil tudi oni za mačko, bo seveda nagradil tiste, ki so mu pomagali k pravilni odločitvi; in če se ni, kaznoval tiste, ki so bili proti.
Tako natreniramo mrežo, da hkrati razpoznava kup različnih objektov.
Zdaj pa pride trik: ko je mreža natrenirana, odstranimo izhodne nevrone. V mrežo damo neko novo sliko in namesto da bi od nje dobili odločitev, ali gre za mačko, hišo ali oblak, preberemo le izhode iz zadnjega skritega nivoja, torej 2048 številk.
V teh 2048 se na nek način skriva opis slike. V teh številkah je zapisano, ali je na sliki mačka, hiša ali oblak … saj so bili izhodni nevroni — dokler jih nismo odstranili — zmožni razlikovati med vsemi temi rečmi. Ker je teh različnih reči toliko in ker so tako raznolike, pa teh 2048 (ali kolikor že številk) ni uporabnih le za razlikovanje med rečmi, za katere je bila mreža trenirana, temveč tudi za druge, ki jih ni videla še nikoli.
Kaj pomeni posamična številka, ne vemo. Vemo pa, da opisujejo vsebino slike. Če nam nekdo prinese 40 slik hiš, med katerimi je deset kraških, deset panonskih, deset alpskih in deset »običajnih«, se te skupine slik po teh številkah nekako razlikujejo. Z običajnimi postopki strojnega učenja (najboljše pa z logistično regresijo, ki je v bistvu enaka enemu nevronu) se računalnik lahko nauči razlikovati med vrstami hiš, tako kot se je med različnimi poklici palčkov, različnimi vrstami štirikotnikov ali različnimi skupinami živali. Edina razlika je, da smo pri živalih vedeli, katero lastnost opisuje posamična spremenljivka (ima dlako? daje mleko?), pri slikah pa tega pač ne vemo.
Velja tudi, da sta podobni sliki opisani s podobnimi številkami. Pri tem na gre podobnost glede na barvo, kompozicijo … temveč za vsebinsko podobnost, saj je bila nevronska mreža trenirana glede na vsebino.
V številki 2048 ni nič magičnega, izkaže pa se, da je to primerno število dimenzij.
Ko opišemo sliko z 2048 številkami, rečemo, da smo jo »vložili« v 2048-dimenzionalni prostor; 2048 številk predstavlja »koordinato« slike v 2048 dimenzionalnem prostoru. Takšnemu rečemo vložitev ali, v angleščini embedding.
Ideja vložitve je splošna: tega ne počnemo le s slikami, temveč tudi z besedami (vsako besedo opišemo z, recimo, 300 številkami, v katerih se skriva pomen besede), zvočnimi posnetki …